
Let’s say you’re writing a cookbook and describing ingredients. For sure you’re going to want to be consistent from one recipe to the next. If you don’t want to confuse your readers, it’s good not to refer to one amount as “a pinch” in one recipe and “a dollop” or “a smidge” in another.
Then you look around and realize that other people are writing cookbooks and they have some standards. That’s not a pinch, to them; it’s a teaspoon to some or 5 milliliters to others. What you call a “chunk” everybody else calls “a quarter cup” or “32 grams.” So, you need to be consistent not just within your own cookbook, but with others’ cookbooks, regardless of the dish being prepared—roasts, stir fries, desserts, soups, etc.
Librarians and archivists in data repositories are learning to think like this as well. Because the data being deposited for reuse has much greater value to their institutions when the metadata attached to it are consistent at the study level, the data level, and the file level.
Metadata for discovery and reuse
Curating data is expensive, so anything that can be done to better justify the expense is a good thing. In my mind, the ultimate justification is having the data reused and cited, which is why the data were deposited in the first place. But the first step is discovering that the data exist.
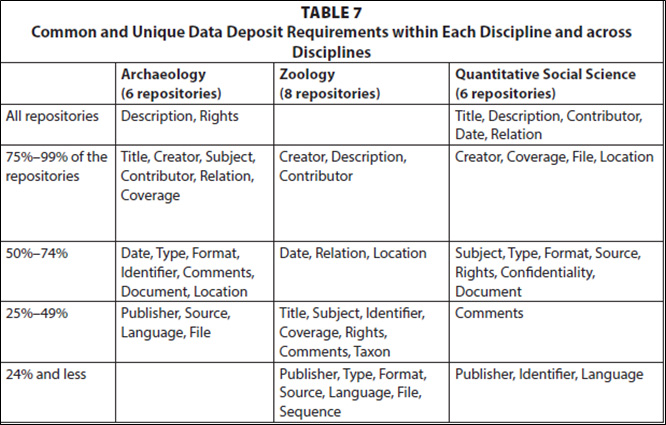
Let’s cook up some metadata consistency. #OCLCnext Share on XIn a recent article I coauthored with Jihyun Kim and Elizabeth Yakel for the College & Research Libraries journal, we found that similar metadata terms across three different disciplines—archaeology, quantitative social science, and zoology—are not used as consistently as they might be. This has implications for discovery and reuse.
It’s not just about having consistency for consistency’s sake
Table 7 from our article exposes some of the metadata inconsistencies we found. More troubling were the inconsistencies in the definitions associated with the metadata terms both within and across disciplines. For instance, the “Coverage” term is defined as a time period. Looking across disciplines, time period may represent the time of data collection or the time period the data covered (e.g., cultural or radiocarbon periods of data). Moreover, as defined and used, “Coverage” overlaps with the “Date” term, another time period that tends to identify data collection dates, but also dates of fieldwork, data deposit dates, donor and curator sign-off dates, and data embargo periods, to name a few.
These types of inconsistencies have repercussions for data discovery and reuse across as well as within disciplines. We don’t have the luxury of building one massive repository that houses all of the data in the world or one gigantic metadata crosswalk engine. So, cataloging for discovery using terms and definitions that are consistent across repositories is critical, if we want the data and their associated metadata to be discoverable for reuse in any way imaginable.
Depositing data with context, ability to interoperate, explanations of usage
We spent quite a lot of time examining the data deposit documentation process. It actually performs the dual purpose of defining a contract between depositors and repositories and gathering information about the deposited data. It’s a critical part of the workflow that underlies all repositories.
Given our findings, we also discuss three implications for data curation and relate them to the FAIR Guiding Principles for scientific data management and stewardship. Specifically:
- The need for sufficient information about context
- The use of standards-based vocabulary to support interoperability
- The need for specific information about the data usage license
This is a complex subject and there’s lots of work to be done. And while data repositories are not always the first type of work that people think of when they consider becoming a librarian or archivist, I hope I can get you excited or at least interested in this one important idea:
Librarians and archivists can help create consistencies in metadata that build bridges between researchers and repositories, thus greatly increasing the discovery, reuse, and value of their institutions’ research investments.
It’s work librarians and archivists are already really good at, just done in exciting new ways. The OCLC Research Library Partnership Metadata Managers Focus Group is one example as members share information about topics of common concern. In 2020, the group plans to discuss the fundamental role of metadata in our research environment from planning research through to creating and managing data, disseminating knowledge, and understanding the impact sharing, curating, and reusing data have on researchers and their institutions.
Bringing deep cataloging experience from the print and digital realms over to data curation is like cooking favorite dishes from childhood all over again. We know the outcomes, we know exactly what the dish should taste like, but the instructions aren’t easily transferable to the modern kitchen. So, we must rely on standards and carefully translate each step for consistency.
This is incredibly important work. And it’s becoming more and more essential as research institutions are looking at ways to leverage their investments and increase the reach of their brands.




Share your comments and questions on Twitter with hashtag #OCLCnext.