
I’ve been talking about linked data a lot lately. Before you say, “Oh, that’s so five minutes ago,” let’s frame linked data technologies and principles as a technology trend in libraries that continues to get (and deserves) extra attention. I’m naturally skeptical when libraries try to apply new technologies to long-solved problems, but I am now thoroughly convinced that the library needs linked data platforms. It’s one of our last chances to embark on innovations that we’ve known for a long time are not possible with the increasingly arcane and anachronistic MARC record.
It’s not always easy to see “what’s in it for me?” in linked data, so let me attempt a view from the many rocks we stand on.
What does “productive linked data” look like?
What could linked data cataloging mean for library workers and end users?
- Catalogers will trade re-work for pioneering new work, refocusing on materials and not on formatting strings, abandon local aggregation and cleanup of others’ data, and integrate “authority work” through more efficient “identity management.”
- Special collections staff will reveal hidden collections, gain methods for handing new or odd formats, encourage the participation of their communities of practice, and surface materials for community experts to enrich.
- Library administrators will free staff from aggregation, cleanup, and authority work; move knowledge work to the cloud; enable more experimentation; and embed the library more deeply in knowledge creation and sharing on their campuses and in their communities.
- End users will encounter context-enriched data, access language and script versatility, find their communities of practice, and discover new pathways of inquiry with an ability to answer questions they didn’t know to ask.
But the path to this kind of productive use of linked data is fraught with fear, uncertainty, and doubt.
From hype to hope
In a talk at CNI last spring, I used the Gartner Hype Cycle to explain where libraries are with linked data (see the 2018 Hype Cycle for Emerging Technologies below). Surprisingly, “Knowledge Graphs” are still climbing the curve to the Peak of Inflated Expectations. I would argue that libraries reached this peak over a year ago with linked data and quickly descended into the Trough of Disillusionment where linked data was in danger of residing until MARC danced on its grave.
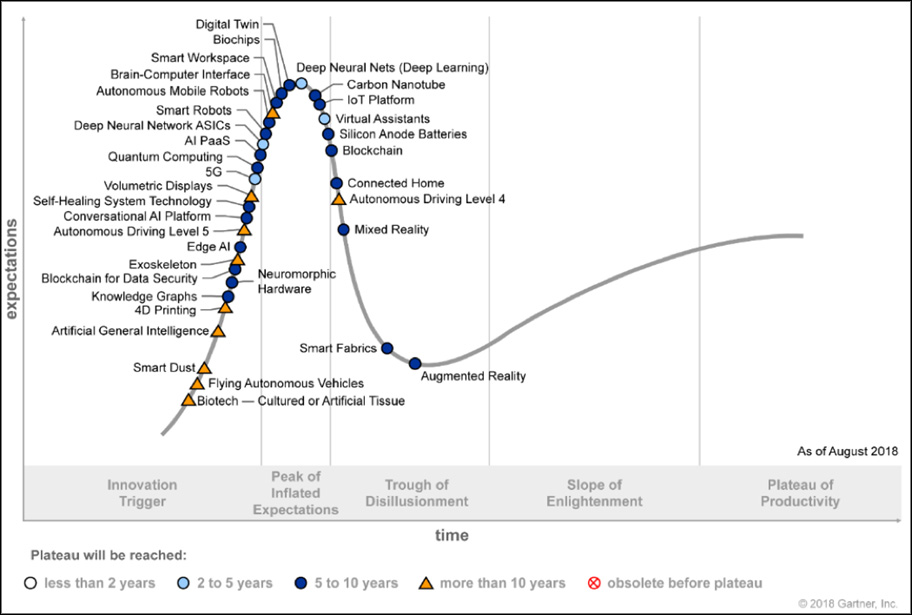
But OCLC and libraries have too much skin in this game to give up so easily. In July, the Mellon Foundation awarded additional grant funds to Stanford University for its “Linked Data for Production” (LD4P) effort. This latest round will focus on productionizing linked data services in libraries. OCLC has spent several years experimenting with linked data. Earlier this year, those experiments took on a new urgency as the library community clamored from that Gartner Trough.
[bctt tweet=”What does the path to productive linked data for libraries look like? #OCLCnext”]
In January 2018, OCLC created a linked data Wikibase prototype, built to view, edit, and create linked data descriptions and relationships, and to reconcile data between legacy bibliographic information and linked data entities. But OCLC Research was not alone in this endeavor. Working closely with 16 academic, research, public, and national institutions, the effort was grounded in a strategy to create scaled, production-level services for libraries to conduct what Kenning Arlitsch has called “new knowledge work.” Check out OCLC’s linked data member story, based on interviews with the prototype participants.

In a parallel effort, OCLC released its first production linked data service when CONTENTdm integrated the International Image Interoperability Framework (IIIF) into its discovery service. The IIIF API allows innovators to view and manipulate digital items regardless of the digital application and repository technology that has been deployed.
Getting to enlightenment
Work continues in earnest to climb Gartner’s Slope of Enlightenment. And expectations are high. OCLC and its library partners completed work on the Wikibase prototype in September, applying lessons learned to planning for and implementing production services for linked data editing and reconciliation.
That planning is currently in the design phase. The prototype team (from OCLC Research, Global Product Management, and Global Technologies) is consulting on the final architecture, with priority placed on building an entity ecosystem and related services. In the meantime, OCLC Research will produce several new reports on the realistic promise of linked data in libraries. Keep an eye out for the following:
- Linked data survey: “Analysis of the 2018 International linked data Survey for Implementers,” published in Issue 42 of the Code4Lib Journal.
- Linked data prototype: a full technical and functional report on the linked data Wikibase prototype, published by OCLC Research.
- Linked Data Landscape in Europe and the U.S.: an OCLC Research report synthesizing the last five years of linked data research—the state of linked data in libraries, challenges presented in the transition, and pragmatic observations regarding creating a production linked data service for libraries.
Library contribution to linked data will be more than theory, observation, and prototypes. I’m incredibly optimistic that as a community we will not only climb that slope of enlightenment, but we will soon enjoy a plateau of productivity that will benefit libraries, library workers, and our end users.



Share your comments and questions on Twitter with hashtag #OCLCnext.